Inside Git - How It Works and the Role of the .git Folder | Git & GitHub
We use Git commands every day: git init, git add, git commit. But have you ever wondered: How does Git actually remember everything? Where does it store the history? What's really inside that .git folder?
It's not magic. It's just a clever database hidden in plain sight.
The Hidden Database: .git Folder
When you run git init in your project, Git creates a hidden folder named .git. This folder is the brain of your entire version control system.
If you open your terminal and type:
ls -a
You will see the .git folder appear (along with other hidden files). This folder contains your entire project history. If you delete this folder, your project becomes just a regular folder, and all version control is lost.
Important: Never delete the .git folder unless you intentionally want to stop using Git!
Inside the .git Folder: Three Critical Components
The .git folder has several important parts, but three of them matter the most:

Figure 1: The hierarchical structure of the .git folder and its key components.
1. HEAD: Your Current Location
The HEAD file is simple but important. It tells Git which branch you are currently on.
If you check its contents:
cat .git/HEAD
You will see:
ref: refs/heads/main
This means: "You are currently standing on the main branch."
2. refs/heads/main: The Commit Pointer
Inside the .git/refs/heads/ folder, there are files for each branch. Let's look at the main file:
cat .git/refs/heads/main
Output:
abc123def456xyz789abc123def456xyz789abc123
This is a commit hash ID. This specific string points to your latest commit on the main branch.
Here's the connection: This is exactly the same hash that appears when you run:
git log --oneline
Why this matters: Git doesn't need to search for your latest commit. It already knows where it is because it's stored in this file!
3. objects: The Data Storage
This is where the actual magic happens. The .git/objects/ folder contains all the real commit data:
Tree objects: Snapshots of your file structure.
Commit objects: Author, date, message, and parent commit.
Blob objects: The actual file contents.
When you run git log or git diff, Git retrieves data from here.
How Git Actually Retrieves Your History
When you run git log, Git doesn't magically pull data from nowhere. It follows a specific path:
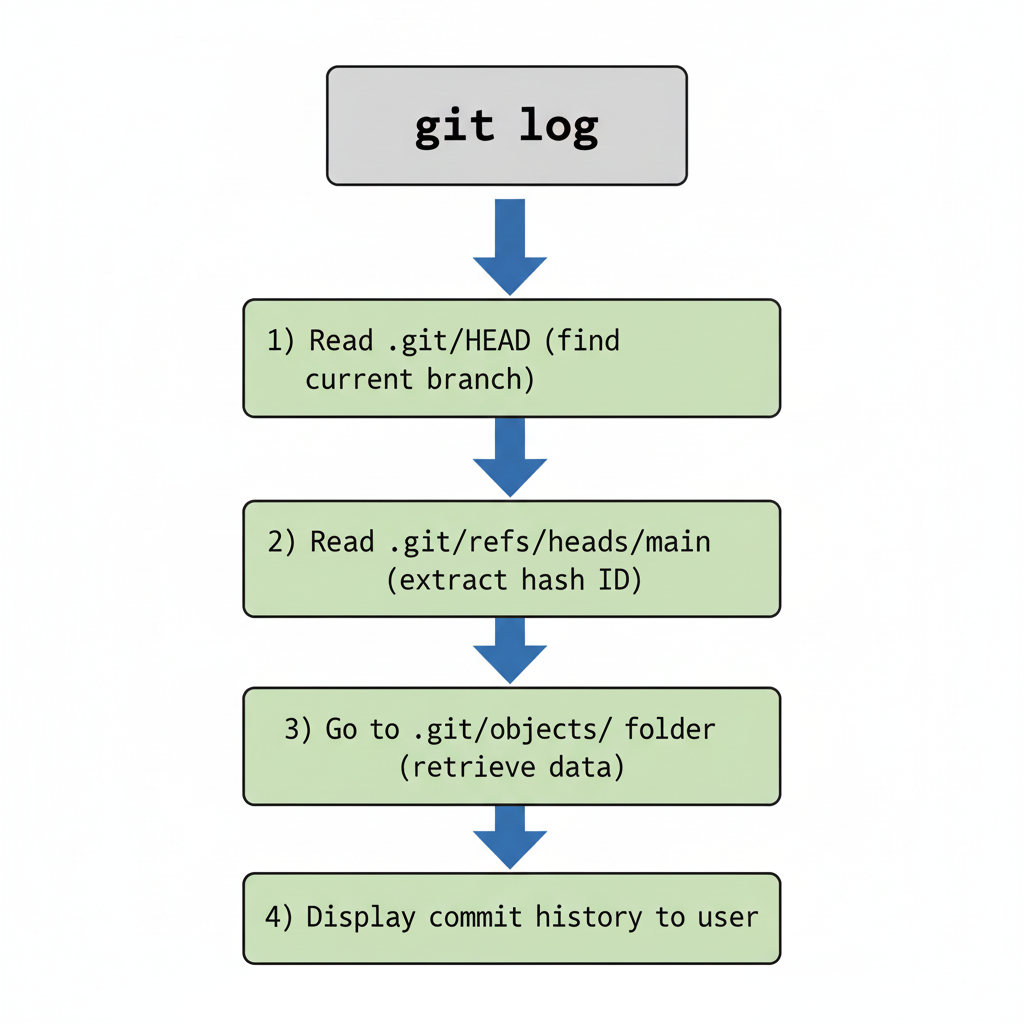
Figure 2: The step-by-step process Git follows when you run 'git log'.
Step-by-step:
Read .git/HEAD: Git checks which branch you're on.
Read .git/refs/heads/main: Git retrieves the latest commit hash.
Go to .git/objects/: Git finds the commit data using that hash.
Display it to you: Git shows you the history in the terminal.
This entire process happens in milliseconds!
Verification: Connecting the Dots
Here's how you can verify that this is actually happening:
Step 1: Get the latest commit hash
cat .git/refs/heads/main
Output: abc123def456...
Step 2: Check what git log shows
git log --oneline
Output:
abc123def (HEAD -> main) Added login feature
Notice: The hash at the beginning is the same! This proves that Git is reading from the .git/refs/heads/main file.
Why This Understanding Matters
Understanding the .git folder structure helps you realize several important truths:
Your code is safe: As long as the
.gitfolder exists, your entire history is preserved.Git is portable: The
.gitfolder is self-contained. You can move your project anywhere, and Git still works.No internet needed: Git works entirely offline. GitHub is optional; Git itself doesn't require the internet.
Commands are shortcuts: When you type
git log, you're essentially asking Git to read and display files from the.gitfolder.
The Complete Picture
The .git folder isn't mysterious—it's just well-organized:
HEAD tells you where you are.
refs point to the latest commits.
objects store the actual data.
When you understand this structure, Git stops feeling like magic and starts feeling like a well-engineered tool.
You can find more of my work at abdulrdeveloper.me
Read more posts at blog.abdulrdeveloper.me


